Claude Agent SDK AI Observability installation
Contents
- 1
Install the PostHog SDK
RequiredSetting up analytics starts with installing the PostHog Python SDK.
- 2
Install the Claude Agent SDK
RequiredInstall the Claude Agent SDK. PostHog instruments your agent queries by wrapping the
query()function. The PostHog SDK does not proxy your calls.Proxy noteThese SDKs do not proxy your calls. They only fire off an async call to PostHog in the background to send the data. You can also use LLM analytics with other SDKs or our API, but you will need to capture the data in the right format. See the schema in the manual capture section for more details.
- 3
Initialize PostHog and run a query
RequiredInitialize PostHog with your project token and host from your project settings, then use the PostHog
query()wrapper as a drop-in replacement forclaude_agent_sdk.query(). This automatically captures$ai_generation,$ai_span, and$ai_traceevents.Notes:
- All original messages are yielded unchanged — the wrapper is fully transparent.
- If you want to capture LLM events anonymously, don't pass a distinct ID. See our docs on anonymous vs identified events to learn more.
You can expect captured
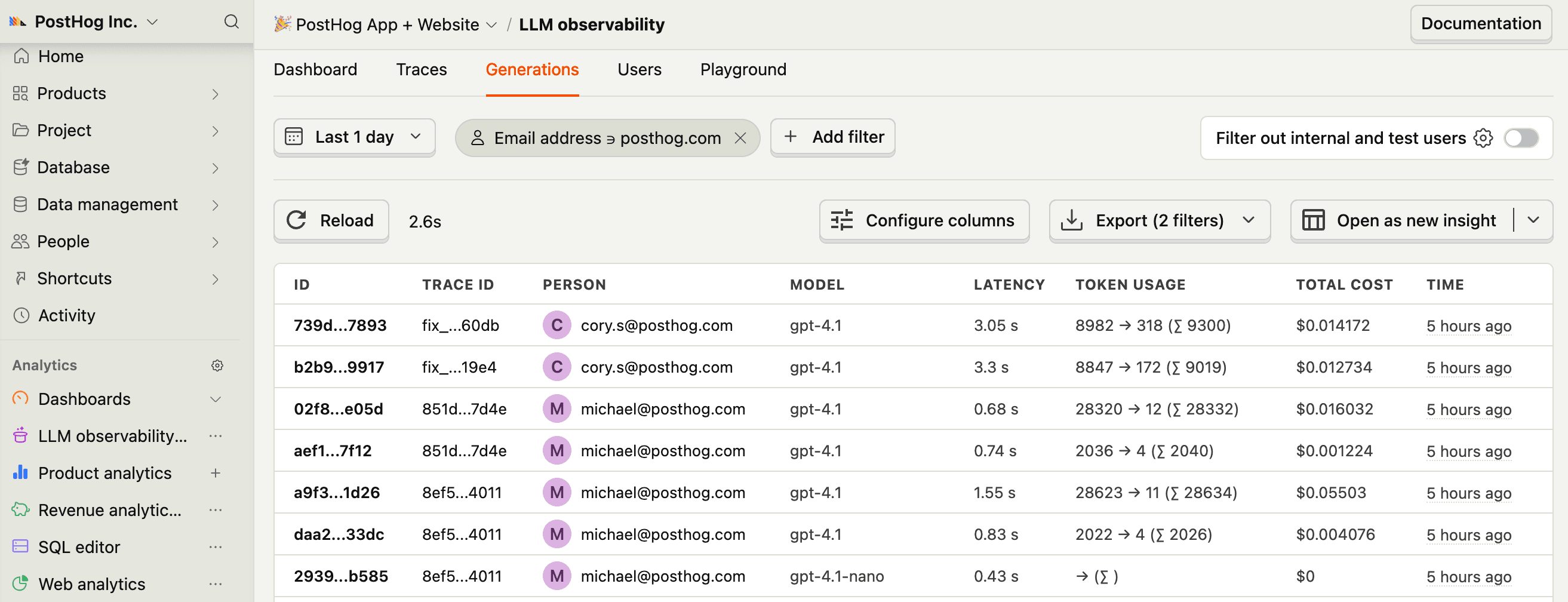
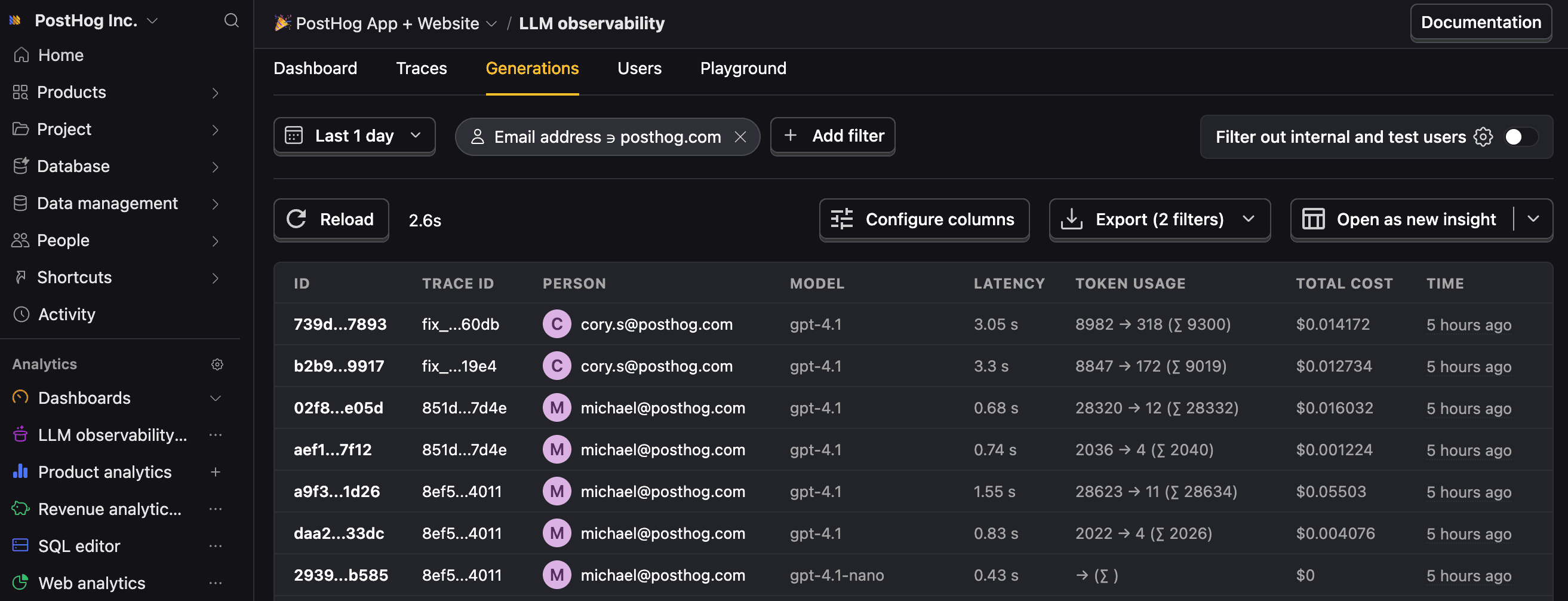
$ai_generationevents to have the following properties:Property Description $ai_modelThe specific model, like gpt-5-miniorclaude-4-sonnet$ai_latencyThe latency of the LLM call in seconds $ai_time_to_first_tokenTime to first token in seconds (streaming only) $ai_toolsTools and functions available to the LLM $ai_inputList of messages sent to the LLM $ai_input_tokensThe number of tokens in the input (often found in response.usage) $ai_output_choicesList of response choices from the LLM $ai_output_tokensThe number of tokens in the output (often found in response.usage)$ai_total_cost_usdThe total cost in USD (input + output) [...] See full list of properties - 4
Reusable configuration with instrument()
OptionalIf you make multiple
query()calls with the same PostHog configuration, useinstrument()to configure once and reuse across queries.You can override any PostHog parameter per-query:
async for msg in ph.query(prompt="...",options=options,posthog_distinct_id="different_user",posthog_properties={"extra": "data"},):... - 5
Tool usage and multi-turn conversations
OptionalPostHog captures the full trace hierarchy for multi-turn agent conversations with tool calls. Each tool use is captured as an
$ai_spanevent linked to its parent generation.This captures:
$ai_generationevents for each LLM turn (with token counts, cost, and cache metrics)$ai_spanevents for each tool use (Read, Glob, Grep, Bash, etc.)- An
$ai_traceevent grouping the entire conversation with total cost and latency
- 6
Multi-turn conversations with history
OptionalFor stateful, multi-turn conversations where each follow-up has full context from previous turns, use
PostHogClaudeSDKClient. This wraps the Claude Agent SDK'sClaudeSDKClientand instruments each turn automatically. All turns share a single trace.Each
receive_response()cycle emits$ai_generationevents for that turn. When the client disconnects (exiting theasync withblock), a single$ai_traceevent is emitted covering the entire session with aggregate latency. - 7
Next steps
RecommendedNow that you're capturing AI conversations, continue with the resources below to learn what else AI Observability enables within the PostHog platform.
Resource Description Basics Learn the basics of how LLM calls become events in PostHog. Generations Read about the $ai_generationevent and its properties.Traces Explore the trace hierarchy and how to use it to debug LLM calls. Spans Review spans and their role in representing individual operations. Anaylze LLM performance Learn how to create dashboards to analyze LLM performance.